Checkers AI
·Alpha-Beta vs. Reinforcement Learning
About
Built this from scratch after my reinforcement learning class. See if you can beat my AI (alpha-beta pruning, depth 4, running Python in your browser via Pyodide)
Key Features
- Q-tables serialized with pickle so the trained policy loads instantly, no retraining
- Hand-tuned evaluation heuristics for the alpha-beta agent
Backend & Infrastructure
RL agent trained across 10,000+ self-play games using reward shaping and epsilon decay. Benchmarked over 5,000 matches to verify policy convergence and tactical improvement over time.
Media
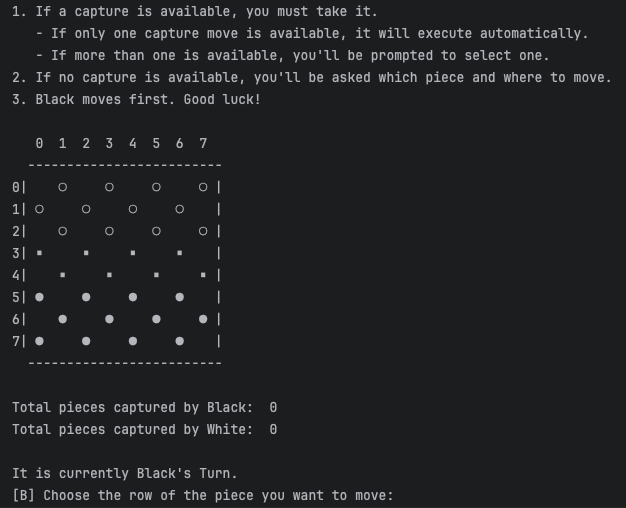
Checkers AI screenshot 1